
mustache
大约 7 分钟
""
什么是模板引擎
以前数据变视图
数组join法
利用数组的.join方法,把数组拼接为字符串,再把字符串放入DOM树中
<ul id="list"></ul>
<script>
var arr = [
{name:'小红',age:13,sex:'女'},
{name:'小强',age:14,sex:'男'},
{name:'小刚',age:15,sex:'男'}
]
let list = document.getElementById('list')
for (let i = 0; i < arr.length; i++) {
list.innerHTML += [
'<li>',
'<div class="hd">'+ arr[i].name +'的基本信息</div>',
'<div class="bd">',
'<p>姓名:'+ arr[i].name +'</p>',
'<p>年龄:'+ arr[i].age +'</p>',
'<p>性别:'+ arr[i].sex +'</p>',
'</div>',
'</li>'
].join('')
}
ES6``法
var arr = [
{name:'小红',age:13,sex:'女'},
{name:'小强',age:14,sex:'男'},
{name:'小刚',age:15,sex:'男'}
]
let list = document.getElementById('list')
for (let i = 0; i < arr.length; i++) {
list.innerHTML += `
<li>
<div class="hd">${arr[i].name}基本信息</div>
<div class="bd">
<p>姓名:${arr[i].name}</p>
<p>年龄:${arr[i].age}</p>
<p>性别:${arr[i].sex}</p>
</div>
</li>
`;
}
mustache基本使用
mustache官方:https://github.com/janl/mustache.js
mustache4.2.0报错解决方法:https://blog.csdn.net/qq_45679015/article/details/119848165
mustache语法:https://www.jianshu.com/p/7f1cecdc27e1
mustache是胡子的意思,因为长得像胡子{{}}
{{}}也被Vue沿用
使用:引入mustache,可以用NPM,也可以CDN引入
循环
<script type="module">
import Mustache from './jslib/mustache.js'
var templateStr = `
<ul>
{{#arr}}
<li>
<div class="hd">{{name}}基本信息</div>
<div class="bd">
<p>姓名:{{name}}</p>
<p>年龄:{{age}}</p>
<p>性别:{{sex}}</p>
</div>
</li>
{{/arr}}
</ul>
`
var data = {
arr: [
{ name: '小红', age: 13, sex: '女' },
{ name: '小强', age: 14, sex: '男' },
{ name: '小刚', age: 15, sex: '男' }
]
}
let divStr = Mustache.render(templateStr, data)
let container = document.getElementById('container')
container.innerHTML = divStr
</script>
简单循环
<script type="module">
import Mustache from './jslib/mustache.js'
var templateStr = `
<ul>
{{#arr}}
<li>
{{.}}
</li>
{{/arr}}
</ul>
`
var data = {
arr: [
"华为","苹果","小米"
]
}
let divStr = Mustache.render(templateStr, data)
let container = document.getElementById('container')
container.innerHTML = divStr
</script>
变量
<script type="module">
import Mustache from './jslib/mustache.js'
var templateStr = `
<h1>我的名字是:{{name}},我今年{{age}}岁了</h1>
`
var data = {
name:'小胖子',
age:15
}
let divStr = Mustache.render(templateStr, data)
let container = document.getElementById('container')
container.innerHTML = divStr
</script>
布尔值
m为true,就会渲染,为false就不会渲染。跟v-if一样
<div id="container"></div>
<script type="module">
import Mustache from './jslib/mustache.js'
var templateStr = `
{{#m}}
<h1>我出来了</h1>
{{/m}}
`
var data = {
m:true
}
let divStr = Mustache.render(templateStr, data)
let container = document.getElementById('container')
container.innerHTML = divStr
</script>
mustache的底层核心机理
基础核心机理replace
使用replace方法,利用正则,来替换字符串模板中的内容,然后返回给DOM树
replace()第一个参数是一个正则表达式,用来查找正则对应的数据,()是用于捕获内容,在第二个参数中,使用$1,$2来获取被捕获的内容。
第二个参数可以以一个方法,这个方法接收几个参数:
- 本次查找到的内容,案例中是:
{{name}}和{{age}} - 本次捕获的内容,案例中是:
name和age - 有多个小括号,就需要有多个
$* - 后一个是索引,本次查找到的对应正则的内容的位置
- 最后一个是本次查找时的
源数据
<div id="container"></div>
<script>
let templateStr = `<h1>我的名字是{{name}},今年{{age}}岁了</h1>`
let data = {
name:'张三',
age:25
}
function render(templateStr,data) {
return templateStr.replace(/\{\{(\w+)\}\}/g,function (findStr,$1) {
return data[$1]
})
}
let result = render(templateStr,data)
let container = document.getElementById('container')
container.innerHTML = result
</script>
但是mustache不是用的简单的正则表达式去实现的。
mustache库的机理
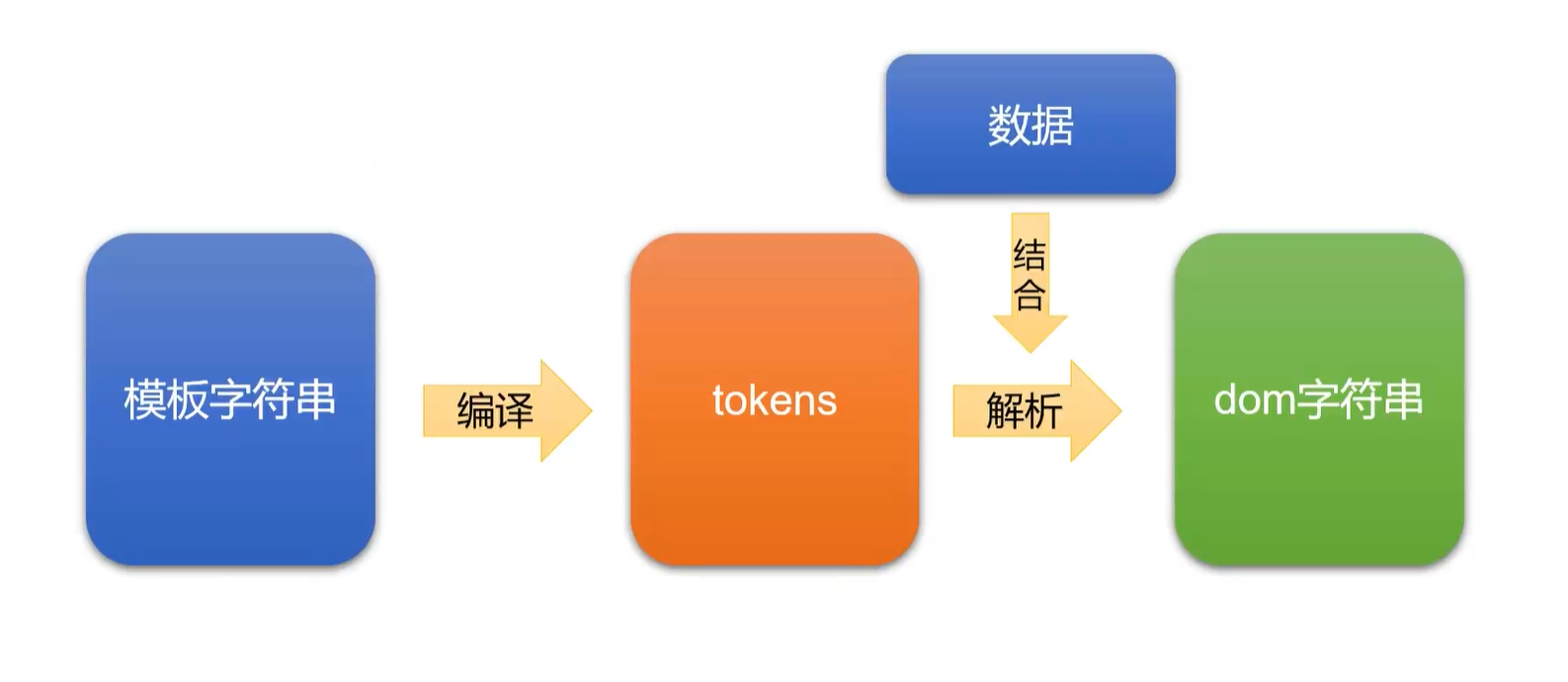
tokens
是一个JS的嵌套数组,把模板字符串转为JS表示
tokens是“抽象语法树”,“虚拟节点”等的开山鼻祖
例如:
模板字符串:
"<h1>我买了一个{{thing}},它需要{{money}}元钱</h1>"
tokens:
[
["text","<h1>我买了一个"], //token
["name","thing"], //token
["text",",它需要"], //token
["name","money"], //token
["name","元钱</h1>"] //token
]
例如:
模板字符串:
`<div>
<ul>
{{#arr}}
<li>{{.}}</li>
{{/arr}}
</ul>
</div>
`
编译tokens:
[
["text","<div><ul>"],
["#","arr",[
["text","<li>"],
["name","."],
["text","</li>"]
]],
["text","</ul></div>"]
]
tokes中的每一项都是一个token.
纯文本会被编译为text,需要渲染的编译为name
手写实现mustache库
环境配置
初始化
npm init -y
安装webpack的包
npm init -D webpack webpack-cli webpack-dev-server
创建webpack配置文件
const path = require('path')
module.exports={
//入口
entry:'./src/index.js',//相对路径
//输出
output:{
//文件名
filename:'bundle.js'
},
devServer: {
//静态资源根目录
static: {
directory: path.join(__dirname, 'www'),
},
//不压缩
compress: false,
//端口号
port: 9000,
},
//模式
mode:'development'
}
创建/src/index.js文件
alert('hello iam mustache');
创建/www/index.html文件
<body>
<h1>hello</h1>
<script src="/bundle.js"></script>
</body>
修改package.json中的script配置:
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"dev": "webpack-dev-server"
},
运行服务:
npm run dev
最后根据提示在浏览器打开
各个模块
index.js
// index.js
import parseTemplateToToken from './parseTemplateToToken'
import renderTemplate from './renderTemplate'
// 全局提供E_Mustache对象
window.E_Mustache = {
// 渲染方法
render(templateStr, data) {
let tokens = parseTemplateToToken(templateStr)
let domStr = renderTemplate(tokens,data)
console.log(domStr);
return domStr
}
}
Scanner.js
/*
Scanner.js
扫描器类
*/
export default class Scanner {
//构造器
constructor(templateStr) {
console.log(templateStr);
//将模板字符串写在实例上
this.templateStr = templateStr
//指针
this.pos = 0;
//尾巴,一开始是模板字符串
this.tail = templateStr
}
// 功能弱,走过指定内容,没有返回值
scan(tag) {
if (this.tail.indexOf(tag) === 0) {
//tag有多长,pos指针就后移几位,如{{ 就是2位
this.pos += tag.length;
//改变尾巴,从当前指针开始,到后面最后所有内容
this.tail = this.templateStr.substring(this.pos)
}
}
//让指针进行扫描,遇见指定内容结束,返回这之间扫描的文字
scanUtil(stopTag) {
//记录执行该方法时,pos指针的位置
const pos_backup = this.pos;
//当尾巴tail的开头是stopTag的时候,就说明该结束了
// 必须要写&&,防止没找到,判断也不停止,导致死循环
while (this.tail.indexOf(stopTag) != 0 && this.eos()) {
this.pos++; //指针后移
this.tail = this.templateStr.substr(this.pos) //尾巴每次都取指针后面的所有内容
}
return this.templateStr.substring(pos_backup, this.pos)
}
// 指针是否已经到头,返回布尔值
eos() {
return this.pos < this.templateStr.length
}
}
parseTemplateToToken
/*
*@Author: EricKiku
*@Date: 2022-10-14 20:10:53
*@Description: 将模板字符串变为tokens数组
*/
import Scanner from './Scanner'
import nestTokens from './nestTokens';
export default function parseTemplateToToken(templateStr) {
let tokens = [];
//创建扫描器
let scanner = new Scanner(templateStr)
let words;
while (scanner.eos()) {
//扫描开始标记出现之前的文字
words = scanner.scanUtil("{{");
//把扫描出来的内容存储到tokens中
if (words != '') {
tokens.push(['text', words]);
}
//略过{{
scanner.scan("{{")
//扫描后括号
words = scanner.scanUtil("}}")
//存储
if (words != '') {
if (words[0] === "#") {
tokens.push(['#', words.substring(1)]);
} else if (words[0] === "/") {
tokens.push(['/', words.substring(1)]);
} else {
tokens.push(['name', words]);
}
}
//略过}}
scanner.scan("}}");
}
return nestTokens(tokens);
// return tokens;
}
nestTokens
// /*
// *@Author: EricKiku
// *@Date: 2022-10-15 14:51:08
// *@Description: 功能:折叠tokens,把#和/之间的tokens放在#token的第三个索引处
// */
export default function nestTokens(tokens) {
//空的折叠之后的tokens
let nestedTokens = [];
//栈结构,存放tokens中为数组的token
let sections=[]
//收集器,开始指向完整的tokens,由于是指向对象,所以collector和nestedTokens指向同一个数组,一个变化,另一个也变化
let collector = nestedTokens
for (let i = 0; i < tokens.length; i++) {
//取出每一项token['text',"<h1>..."]
let token = tokens[i]
switch (token[0]) {
case '#':
//在收集器中存入该token
collector.push(token)
//入栈
sections.push(token)
//收集器改变指向的数组,变为该token的[2]的空数组
token[2] = []
collector = token[2]
break;
case '/':
//出栈,会返回弹出的项
let section_pop = sections.pop();
//收集器变为栈结构更深一层的项的下标[2]的数组
collector = sections.length > 0 ? sections[sections.length -1][2] : nestedTokens
break;
default:
collector.push(token)
}
}
return nestedTokens
}
renderTemplate
/*
*@Author: EricKiku
*@Date: 2022-10-15 18:03:18
*@Description: 功能:让tokens和数据结合,变为dom字符串
*/
import lookup from "./lookup";
import parseArray from "./parseArray";
export default function renderTemplate(tokens,data) {
console.log(tokens);
let resultStr = ''
//遍历tokens
for (let i = 0; i < tokens.length; i++) {
let token = tokens[i]
//判断是text还是name还是#
if (token[0] ==='name') {
resultStr += lookup(data,token[1])
}else if(token[0] === 'text'){
resultStr += token[1]
}else if(token[0] === '#'){
resultStr += parseArray(token,data)
}
}
return resultStr
}
lookup
/*
*@Author: EricKiku
*@Date: 2022-10-15 18:35:28
*@Description: 功能:把对象中的“.”,处理一下。obj['a.b.c']是不可用的,想要访问深层次的属性,想要lookup方法
*/
export default function lookup(dataObj,keyName) {
//查看属性中是否使用了点,但是keyName还不能是"."本身
if (keyName.indexOf('.') !=-1 && keyName != '.') {
//有“.”时:把点拆开,去访问深层次属性
let keys = keyName.split('.')
let temp = dataObj
for (let i = 0; i < keys.length; i++) {
temp = temp[keys[i]];
}
return temp
}
//如果没有.
return dataObj[keyName]
}
parseArray
/*
*@Author: EricKiku
*@Date: 2022-10-15 19:06:35
*@Description: 功能:处理递归时的token
*/
import lookup from "./lookup";
import renderTemplate from "./renderTemplate";
export default function parseArray(token,data) {
console.log(token,data);
//通过lookup获取对应的数据
let value = lookup(data,token[1]);
//返回的字符串
let resultStr =''
//遍历获取的数据
for (let i = 0; i < value.length; i++) {
resultStr += renderTemplate(token[2],{
'.':value[i],
...value[i]
})
}
// console.log('value:',value);
return resultStr
}