
Js进阶
""
快捷键
alt+shift+r | 统一重命名(webStrom) |
null和undefined区别
null: 定义变量了,并且给变量赋值null
undefined:定义变量,但是没有赋值
什么时候会用到
null
初始化对象,在未获取数据时,可以先用
let obj = null,之后获取数据了再赋值在对象没有用处时,使用
let obj = null,可以释放内存
变量赋值
1.多个引用变量指向同一个对象,通过让一个变量修改这个对象的内部数据,其他所有变量都看见修改之后的数据
let per = {name:"tom"};
function fun(obj) {
obj.name = "jimey";
}
fun(per);
console.log(per.name);//输出jimey
2.多个引用变量指向同一个对象,让其中一个引用变量指向另一个对象,其他变量依然指向前一个变量
let per = {name:"tom"};
function fun(obj) {
obj = {name:"zs"};
}
fun(per);
console.log(per.name);//输出Tom
3.在js调用函数时,传递变量参数是 按值传递
- 基本变量是传值
- 引用变量是传值,值是指向对象的地址
JS引擎管理内存
生命周期
1.分配内存空间,得到使用权
2.存储数据
3.释放内存空间
局部变量在函数执行完毕后自动释放
回调函数
回调函数就是:定义之后的函数,没有调用,但是会执行
DOM事件回调函数
document.getElementById("btn").onclick = function(){
alert("btn")
}
定时器回调函数
setInterval(function(){
alert("time")
},1000)
Ajax请求回调函数
生命周期回调函数
IIFE立即执行函数
函数不需要函数名,可以直接执行
作用:隐藏实现。不会污染全局命名空间
(function(){
alert("fun")
})()
this
什么是
this
所有函数内部都有一个变量this,值是调用该函数的当前对象
没有指定对象,就是window调用
如何确定
this的值
| 代码 | this指向 |
|---|---|
fun() | window |
obj.fun() | obj |
let obj = new Fun() | obj |
fun().claa(newObj) | newObj,是一个隐式传参,不会传递给形参 |
代码前加分号
有两种情况不加分号会出问题
- 小括号开头的前一句代码
- 中括号和方括号开头的前一条语句
console.log("我是前")
(function () {
console.log("fun");
})();
这样会导致第一行的语句会报错,原因是浏览器会压缩js文件,导致前一行与后一行并起来,导致出错
解决方法:在后一个括号前加分号
console.log("我是前")
;(function () {
console.log("fun");
})();
有时会在代码第一行前加一个分号,是为了防止js合并时,前一个js文件的末尾没有分号,导致出错
原型
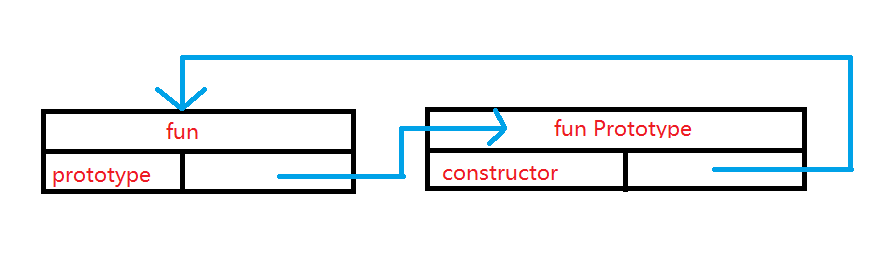
每一个函数都有一个prototype属性,指向该函数的原型对象
每个函数的原型对象中都有一个属性constructor,指向该原型对象的实例
所有函数的显示原型对象的__proto__都指向Object.prototype,除了Object
显示原型和隐式原型
1、每个函数function都有一个prototype,即显示原型
function fun(){}
console.log(fun.prototype)
2、每个实例对象都有一个__proto__,即隐式原型
function Fun(){}
let per = new Fun();
console.log(per.__proto__);
3、对象的隐式原型的值等于其对应构造函数的显示原型的值
Fun.protptype === per.__proto__
原型链:
__proto__别名:隐式原型链
作用:查找对象的属性、方法
访问一个对象的属性时,先在自身找,找不到时就会沿着__proto__链表向上查找,找到并返回,如果最终没有找到,返回undefined
图解:
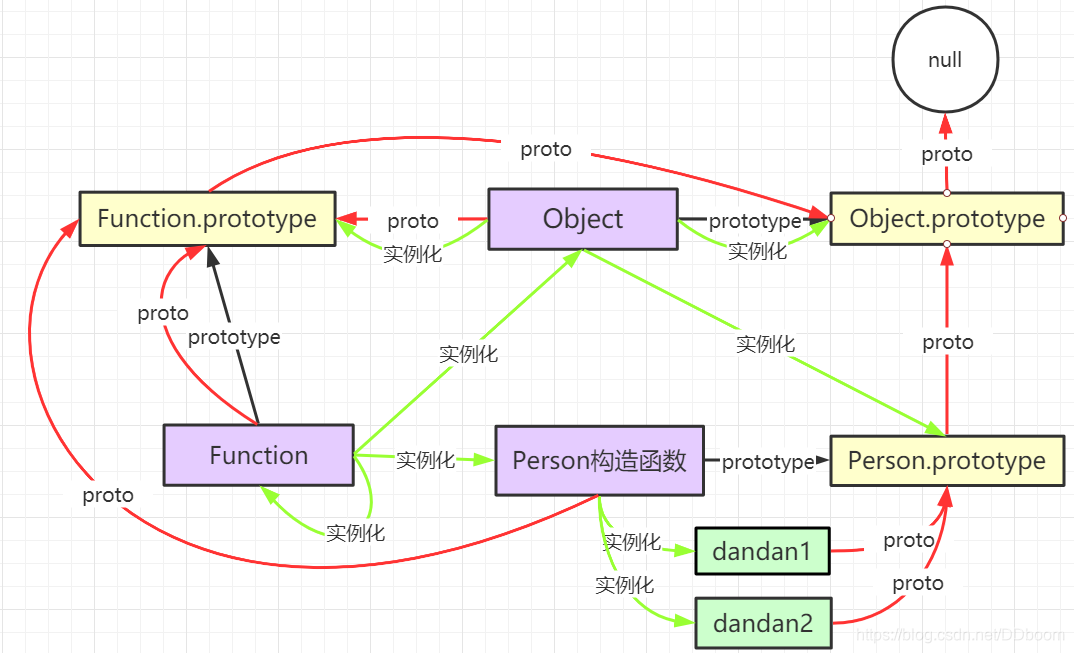
解释:所有的函数的__proto__都指向Function.prototype,因为所有的函数都是由Function实例化出来的,Function.prototype的__proto__属性指向终点Object.prototype,只有实例化对象的__proto__指向构造函数的prototype
Function.__proto__ === Function.prototype
Object.__proto__ === Function.prototype
Person.__proto__ === Function.prototype
Function.prototype.__proto__ === Object.prototype
p1.__proto__ === Person.prototype
Person.prototype.__proto__ === Object.prototype
所有的函数的prototype都指向自身的prototype,除了Object.prototype属性之外,所有函数的prototype.__proto__都指向Object.prototype。Object.prototype.__ptoto__指向的是null,所以Obejct.prototype相当于原型链的终点
Function.prototype === Function.prototype
Object.prototype === Object.prototype
Person.prototype === Person.prototype
Function.prototype.__proto__ === Object.prototype
Person.prototype.__proto__ === Object.prototype
Object.prototype.__proto__ === null
属性
只有读取属性时,在本身找不到才会去原型链上去找,添加属性时,会在本身添加
function Fn(){}
Fn.prototype.a = "x"
let fn1 = new Fn();
let fn2 = new Fn();
fn2.a = "y"
console.log(fn1.a);//"x"
console.log(fn2.a);//"y"
上面代码的原因是,fn1.a是在原型里找的,而fn2.a="y",是在自身的属性里添加的,所以不会修改原型里的属性
instanceof
A instanceof B
对象 instanceof 构造函数
A 是实例对象,B是构造函数:如果B函数的显式原型对象在A对象的原型链上,返回true,否则返回false
B只往原型prototype走一次,A从__proto__开始走,如果找到B,则返回true
原型面试题
一
function A() {
}
A.prototype.n =1;
let b = new A();
A.prototype = {
n:2,
m:3
}
let c = new A();
console.log(b.n,b.m,c.n,c.m);//1 undefined 2 3
原先A.prototype指向一个对象,并添加属性n,在创建对象b的时候,在源码中是b.__proto__ = A.prototype这么操作,所以对象b可以访问属性n。
之后A.prototype指向了另一个对象,再创建对象c的时候,依然c.__proto__ = A.prototype这么操作,所以c可以访问新创建的对象,而b依然指向旧的对象。
二
let F = function(){}
Object.prototype.a = function () {
console.log("a()");
}
Function.prototype.b = function () {
console.log("b()");
}
let f = new F();
f.a();
f.b();
F.a();
F.b();
结果:
a()
f.b is not a function
a()
b()
变量提升
通过var声明的变量,在定义之前就可以访问,值是undefined
通过function声明的函数,在声明之前就可以调用 同名的话,先提升变量,后提升函数
var fn = function(){}
上面的代码就不能函数提升,因为是变量
提升原因
-----> 在执行全局代码前,将window确定为全局执行上下文
对全局数据进行预处理
1.var定义的全局变量,设置值为undefined,并且添加为window的属性
2.function声明的全局函数,设置值为(fun),并添加为window的方法
3.this指向window
----> 在执行函数上下文
对局部数据进行预处理
1.把实参赋值给形参,添加给执行上下文的属性
2.arguments赋值,值是实参列表,伪数组,添加为执行上下文的属性
3.var、function声明提升
4.this赋值,值是调用函数的对象
全局和函数上下文
1.全局执行上下文一般由浏览器创建,代码执行时就会创建;函数执行上下文只有函数被调用时才会创建,调用多少次函数就会创建多少上下文。
2.调用栈用于存放所有执行上下文,满足FILO规则。
3.执行上下文创建阶段分为绑定this,创建词法环境,变量环境三步,两者区别在于词法环境存放函数声明与const let声明的变量,而变量环境只存储var声明的变量。
4.词法环境主要由环境记录与外部环境引入记录两个部分组成,全局上下文与函数上下文的外部环境引入记录不一样,全局为null,函数为全局环境或者其它函数环境。环境记录也不一样,全局叫对象环境记录,函数叫声明性环境记录。
5.你应该明白了为什么会存在变量提升,函数提升,而let const没有。
6.ES3之前的变量对象与活动对象的概念在ES5之后由词法环境,变量环境来解释,两者概念不冲突,后者理解更为通俗易懂。
执行上下文面试题
一、
console.log("global begin:"+i);
var i = 1;
foo(1);
function foo(i) {
if(i == 4){
return;
}
console.log("foo() begin:" + i);
foo(i + 1 );
console.log("foo() end:" + i);
}
console.log("global end:" + i);
结果:
global begin:undefined
foo() begin:1
foo() begin:2
foo() begin:3
foo() end:3
foo() end:2
foo() end:1
global end:1
二、
function a(){}
var a;
console.log(typeof a) //`function`
变量先提升,函数后提升,所以在栈里是找到函数
if(!(b in window)){
var b = 1;
}
console.log(b) //undefined
在全局上下文中已经var b过了,只不过值是undefined,所以if不成立
var c =1;
function c(c){
console.log(c)
}
c(2); //报错,c不是函数
因为c变量提升,函数也提升并且被扫描过了,不会再执行,所以代码理解应该如下
var c;
function c(c){
console.log(c)
};
c =1;
c(2);
作用域面试题
var x = 10;
function fn(){
console.log(x);
}
function show(f){
var x = 20;
f();
}
show(fn); //10
变量作用域在创建上下文之前就确定了
闭包
对元素循环遍历加监听用闭包实现
let btns = document.getElementsByTagName("button")
for(let i =0,length = btns.length;i< length;i++){
(function (){
var btn = btns[i]
btn.onclick = function(){
alert("第"+i+"个");
}
})(i)
}
如何产生闭包
当一个嵌套的内部函数引用了嵌套的外部函数的变量时,就产生了闭包
闭包到底是什么
嵌套的内部函数
产生闭包的条件
1.嵌套函数
2.内部函数引用了外部函数的数据
代码执行时有几个闭包
闭包的外部函数被调用几次,就是有几个闭包
闭包的作用
如果没有闭包,在调用函数时,函数内部的局部变量在函数执行完毕之后会释放,导致调用该函数的背部函数时,如果内部函数调用了外部函数已经释放的变量,就会报错,有了闭包之后,就不会报错
闭包的作用:
1.使用函数内部的变量在函数执行完之后,任然存活在内存中
2.让函数外部可以操作函数内部的数据
只要存在闭包,也就是内部函数引用过外部函数中的数据,那么在外部函数调用完之后,被引用的数据不会消失,因为存在闭包
闭包的生命周期
产生:在嵌套内部函数定义执行完时就产生了,不是调用的时候
死亡:在嵌套的内部函数成为垃圾对象时
缺点
如果闭包一直存在,数据就一直得不到释放,如果数据占用的空间比较大的话,就会造成内存溢出,
方法:把保存闭包函数的变量的值,设为null
面试题
let name = "The Window"
let object = {
name:"My Object",
getName:function(){
return function(){
return this.name
}
}
}
console.log(objet.getName()()); //The Window
就近原则,object.getName()返回的是一个函数,这个返回的函数没有对象调用它,所以this指的window
let name = "The Window"
let object = {
name:"My Object",
getName:function(){
let that = this;
return function(){
return that.name
}
}
}
console.log(objet.getName()()); //My Object
运用了闭包,当
object.getName()执行的时候,this指的是object,因为getName属性就是一个函数,相当于object.function(){},所以this指的object,然后用that保存了this,运用闭包原则,这个that被内部函数引用,所以没有释放,最终返回My Object
function fun(n,o) {
console.log(o);
return {
fun:function (m) {
return fun(m,n);
}
};
}
let a = fun(0); a.fun(1); a.fun(2); a.fun(3);
let b = fun(0).fun(1).fun(2).fun(3);
let c = fun(0).fun(1); c.fun(2); c.fun(3);
结果:
undefined 0 0 0
undefined 0 1 2
undefined 0 1 1
因为变量
n,所以内部函数形成闭包
对象创建模式
1.
Object构造函数模式
使用场景:一开始不确定对象内部数据
缺点:代码多
let p = new Object();
p.name = "zs";
p.age=12;
p.setName = function(){}
2.
对象字面量
使用场景:起始对象的内部数据是确定的
缺点:多个对象代码重复
let p = {name:"zs",age:12,setName:function(){}}
3.
工厂模式
返回一个对象的函数都可以叫做工厂函数
使用场景:需要创建多个对象
缺点:类型无法修改,都是规定好的
function createPerson(name,age){
let obj = {
name:name,
age:age,
setName:function(name){
this.name = name
}
}
return obj;
}
let p1 = createPerson("zs",12);
let p2 = createPerson("lisi",12);
4.
自定义构造函数
使用场景:需要多个类型的对象
缺点:每个对象都有相同的数据,浪费内存,可以把相同的方法放在原型对象上
通过new构造函数
function Person(name.age){
this.name = name;
this.age = age;
this.setName = function(){
this.name = name;
}
}
let p1 = new Person("zs",12);
5.
构造函数+原型
在构造函数中只初始化一般函数
function Person(name.age){
this.name = name;
this.age = age;
}
Person.prototype.setName = function(){
this.name = name;
}
let p1 = new Person("zs",12);
原型链继承
继承关键:子类型的原型成为父类型的一个实例对象
function Person(name,age){ //父类型
this.name = name;
this.age = age;
}
Person.prototype.setName = function(name){
this.name = name;
}
function Student(name,age){
this.name = name;
this.age = age;
}
Student.prototype = new Person();
let stu = new Sun();
stu.setName();
本来Student.prototype.__proto__应该指向Object.prototype,因为所有的prototype.__proto__都指向Object.prototype.
但是把Student.prototype指向Person的实例,那么Student.prototype.__proto__ === Person.prototype,所以就可以访问Person函数原型上的方法
- 但是这样会让
Student.constructor指向Person,这个是不对的,所以在13行下加上
Student.prototype.constructor = Student
组合继承
function Person(name,age){ //父类型
this.name = name;
this.age = age;
}
Person.prototype.setName = function(name){
this.name = name;
}
function Student(name,age,price){
Person(this,name,age)
this.price = price
}
Student.prototype = new Person();
Student.prototype.constructor = Student;
let stu = new Sun();
stu.setName();
通过在子函数里调用父函数,然后再加上原型链继承的两句话,就是组合继承
Person(this,...)是为了获取父函数里的属性
Student.prototype = new Person(); Student.prototype.constructor = Student;这两句是为了获取父函数里的方法
线程和进程
Web Worders 是H5提供的js多线程方案
可以将计算量大的代码放在web Worders中不冻结界面
但是子线程中不能操作DOM,所以说并没有改变JS单线程的本质
使用:1.创建在分线程执行的js文件。2.在主线程的js中发消息并设置回调函数
使用Worker创建多线程
主线程和子线程都使用postMessage()来向对方发送消息
都使用onmessage来监听参数的变化
index.html 使用let worker = new Worker(js file url)来创建一个线程对象,参数是js文件路径
使用worker.postMessage(value)来发送数据到线程
使用worker.onmessage = function(event){}来设置监听,当有数据返回时触发回调函数,其中event是用来携带参数的,event.data返回的就是参数
let input = document.getElementById("input");
input.value = 10;
let btn = document.getElementById("btn");
btn.onclick = function () {
let value = input.value;
console.log(value);
let worker = new Worker("worker.js")
worker.postMessage(value);
worker.onmessage = function (event) {
alert(event.data);
console.log(event.data);
}
}
worker.js
使用var onmessage = function(event){}来监听传输参数时,触发回调函数,event.data就是传输来的参数,经过计算之后通过postMessage(value)返回参数
var onmessage = function(event) {
let valueWork = event.data;
let result = fibonacci(valueWork);
postMessage(result+"www");
}
function fibonacci(n) {
return n<=2?1:fibonacci(n-1) + fibonacci(n-2)
}
子线程中没有window,所以不能使用alert()、document()等,子线程的this指的是一个Worder对象。所以在子线程中不能更新界面
缺点:不是支持所有浏览器,不能更新DOM,慢,不能跨域加载js